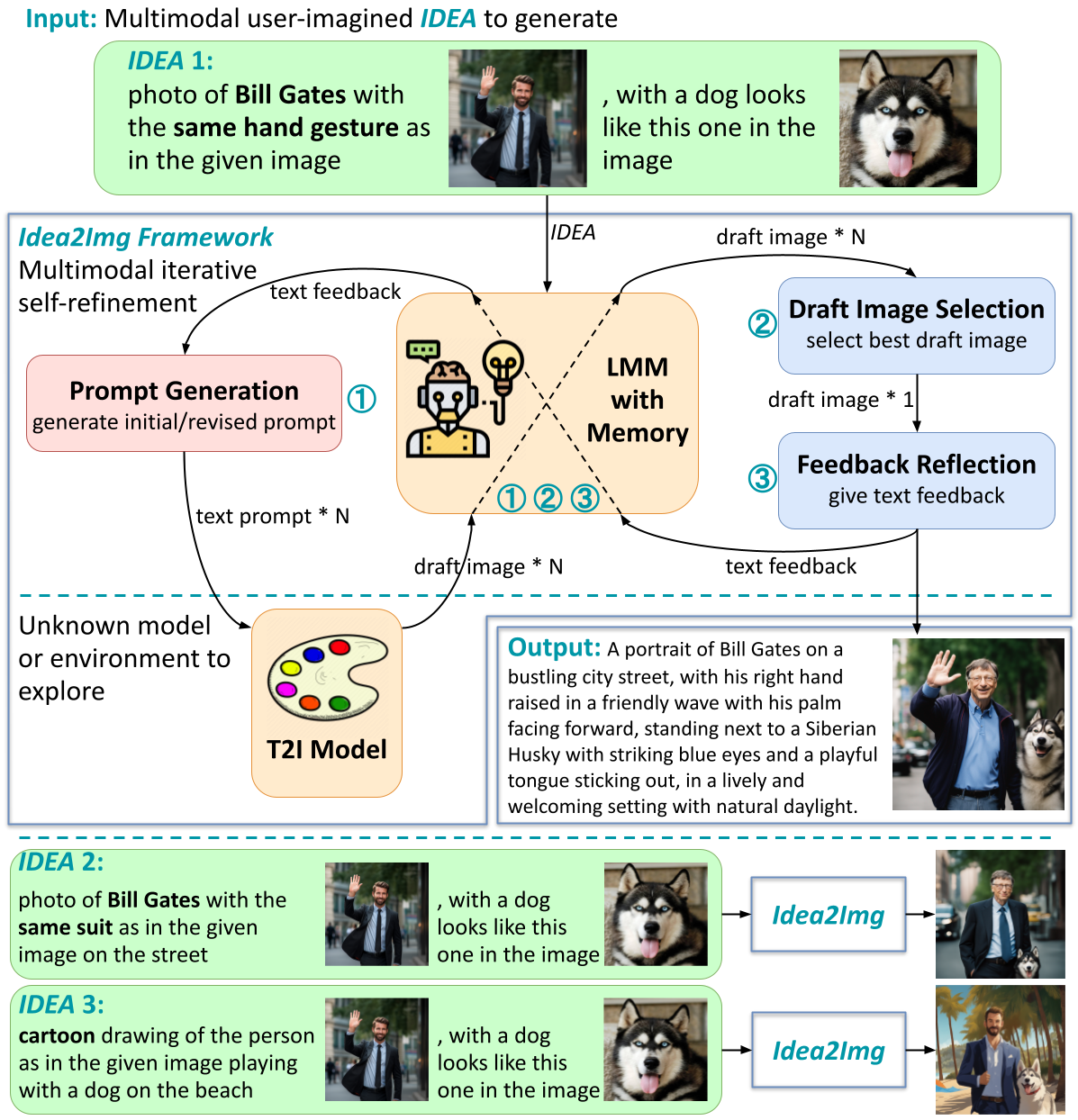
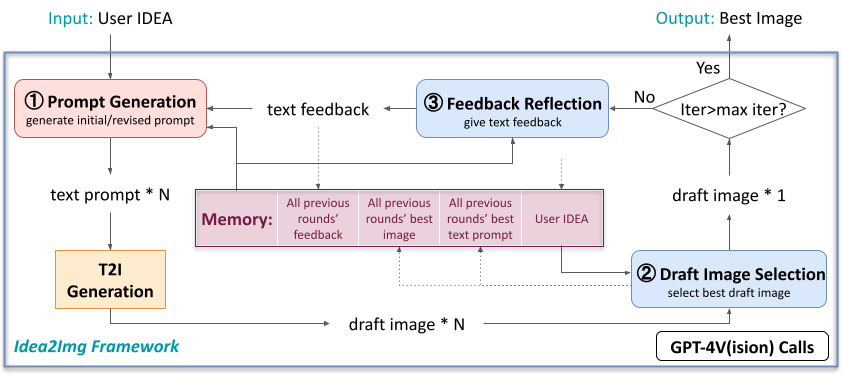
Idea2Img 
Iterative Self-Refinement with GPT-4V(ision)
for Automatic Image Design and Generation
,
,
,
,
,
,